BHoM Toolkits¶
The source code of BHoM is hosted under the public GitHub organisation: https://github.com/BHoM
The organisation hosts a number of repositories. Most of them have a name finishing with "_Toolkit". Foundational repositories are instead called BHoM, BHoM_Engine, BHoM_Adapter, BHoM_UI, among others. The Toolkits are the things that host the actual code, with specific terminologies (object Models, oMs), functionalities (Engines) and translators (Adapters).
Before we discuss in more detail the individual repositories and what they contain, let's take a step back and look at the different categories of code/functionality we can find inside them.
The four categories of code¶
If you ever have created your own tool or script, you must have been exposed to the two dual aspects of computation: data and functionality. In Excel, data would be the value of your cells and functionality would be the formulas or VB scripts. In Grasshopper, the functionality is made by the components, and the data is stored within parameters.
Data is generally representing specific concepts. For example, Grasshopper provides definitions for Points, Lines, etc., which are geometrical concepts. There are however a lot of objects that we manipulate regularly as engineers that are not defined out of the box in any of those programs. So our first category of code will focus on that: providing a list of properties that fully define each type of object we use. For example, we can all agree that a point would have three properties (X,Y, and Z) each representing to position of the point along one axis. This applies similarly to agree on the definitions of elements such as walls, spaces, speakers,...
Manipulators are the bespoke scripts, algorithms, equations, ... that we had to write ourselves to provide calculations not readily available. As engineers we have all had some of those custom made solutions lying around on our computer. Here we simply provide a central place to collect and store them in an organised way so we can all benefit from it.
The two categories above are called respectively oM (stands for object model) and Engine. They are all we need to extend our internal computational capability. That being said, we have no intention to reinvent the wheel by replacing external software like Revit, Robot, Tas, IES,... We are also keen to keep using the user interfaces that we already know like Excel, Grasshopper. We are therefore adding two more categories to our central code. Adapters to allow the exchange of data between our internal code and external softwares. UI plugins to typical programs like Grasshopper that expose all our code directly.
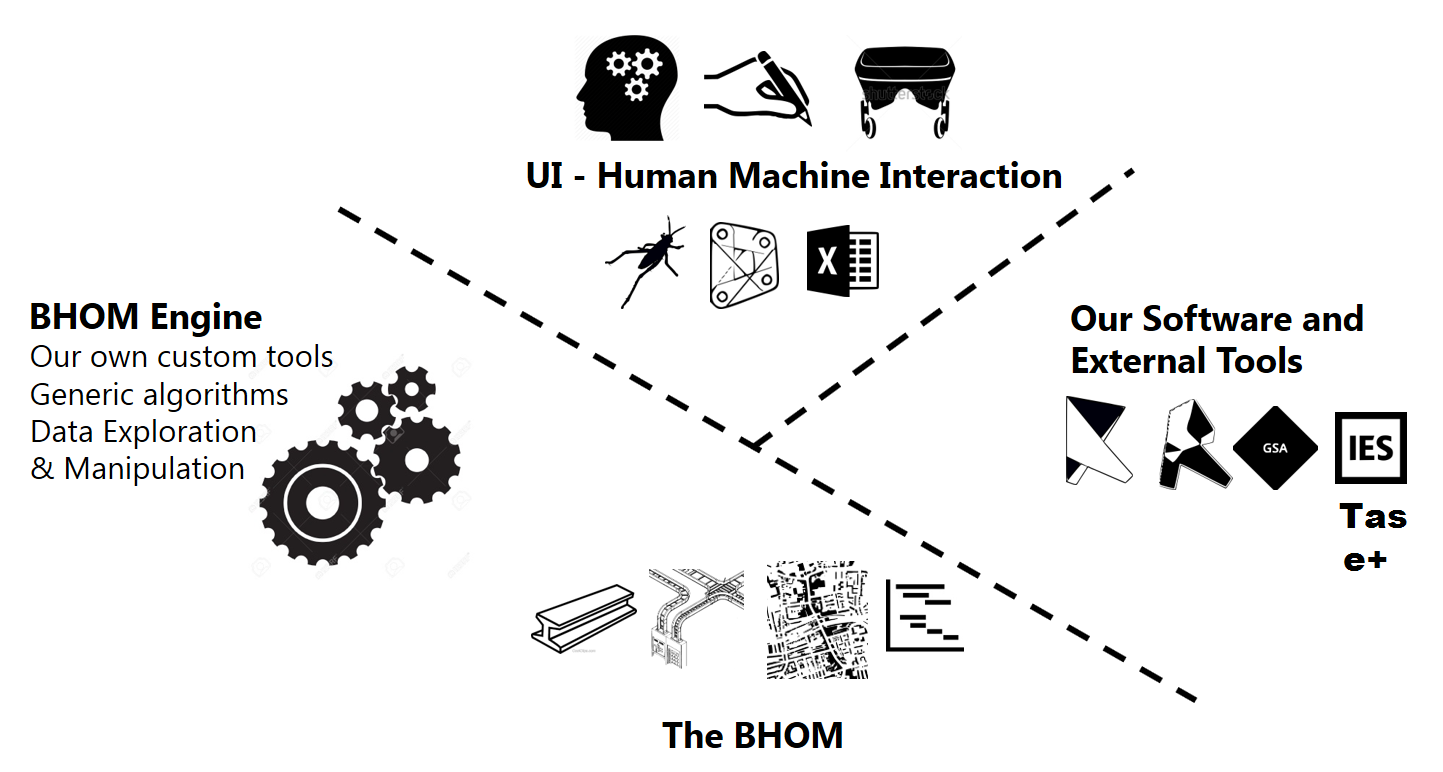
In summary, the four categories of code, you will find among those repositories are:
-
oM: Definitions of the data we manipulate (e.g. Beam, Wall, Speaker,…)
-
Engine: Our own custom tools, algorithms, data exploration & manipulation.
-
Adapter: Connections between the BHoM and engineering tools such as Revit, GSA, Tas, IES,... This is where BHoM objects are translated to and from the proprietary representation used in each of those tools.
-
UI: Expose the BHoM functionality through user interfaces such as Grasshopper and Excel.
Dependency chain¶

The concept of a toolkit¶
The BHoM is designed to be extendable. We want anyone to be able to create a set of tools relevant to a specific task (e.g. linking to another external software, providing a set of discipline specific functionality, ...). This is where the repository come in. They are independent units of development with their own team of developers responsible for maintaining the code in the long run. We call them toolkits.
Internally, they will all follow the same conventions about the four categories of code defined above. To get slightly more into details regarding how that code is structure, let's talk for a second about how those different parts of the code are related to each other.
-
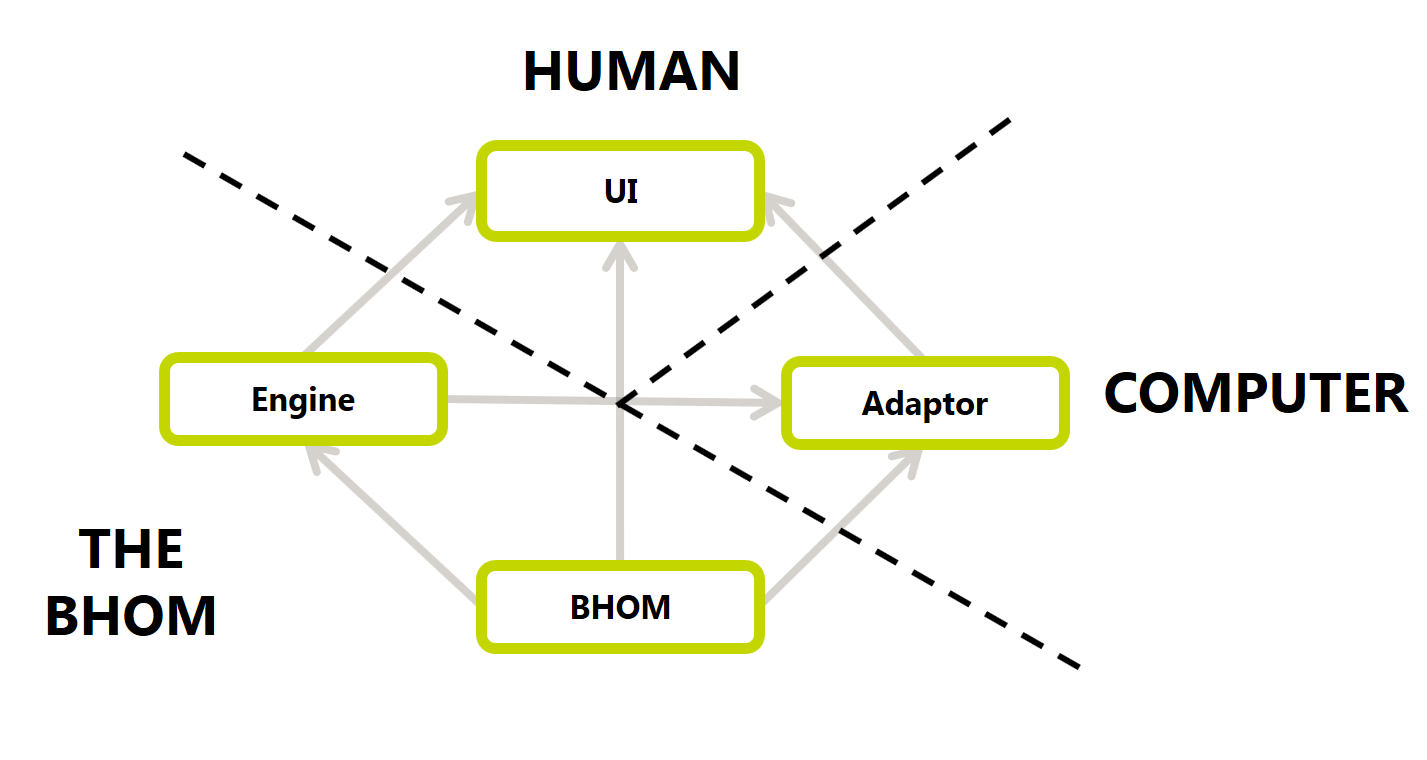
oM: You could see this as our base specialised vocabulary. It doesn't depend on anything else but everything else will rely on the definitions it contains.
-
Engine: Depends only on the oM. Since this is an internal engine, it doesn't have to be aware of any external software or UI.
-
Adapters: The adapter will depend on the oM for the objects definitions and on the engine for the conversion methods
-
UI: Depends on everything else since it will expose all the functionality above to the UI.
Here's what it looks like in a diagram. To be concise, we will refer to this diagram as the diamond in the future.
Be aware that most of the toolkits will not implement all four categories. Let's look at a few user cases:
-
Adapter_Toolkit: E.g. Revit_Toolkit, TAS_Toolkit, GSA_Toolkit,… In there, you will very likely only implement the Adapter category (for the link with the external software) and the Engine category (for the conversion).
-
UI_Toolkit: E.g. Grasshopper_UI, Excel_UI,... In all likelihood, you will only have to worry about the UI category. You might create and Engine for calculations only relevant to that UI but, most of the time, you'll find it is not needed.
-
ProjectType_Toolkit: CableNetDesign_Toolkit, SportVenueEvent_Toolkit,… Focus on providing addition functionality specific to a project type. Provides addition object definitions in the oM and algorithms in the Engine. Nothing on the adapter or UI side is needed.
You will find more details on the specific code structure and conventions to follow for each category in the Further reading section but this is probably enough detail for now.
Core repositories¶
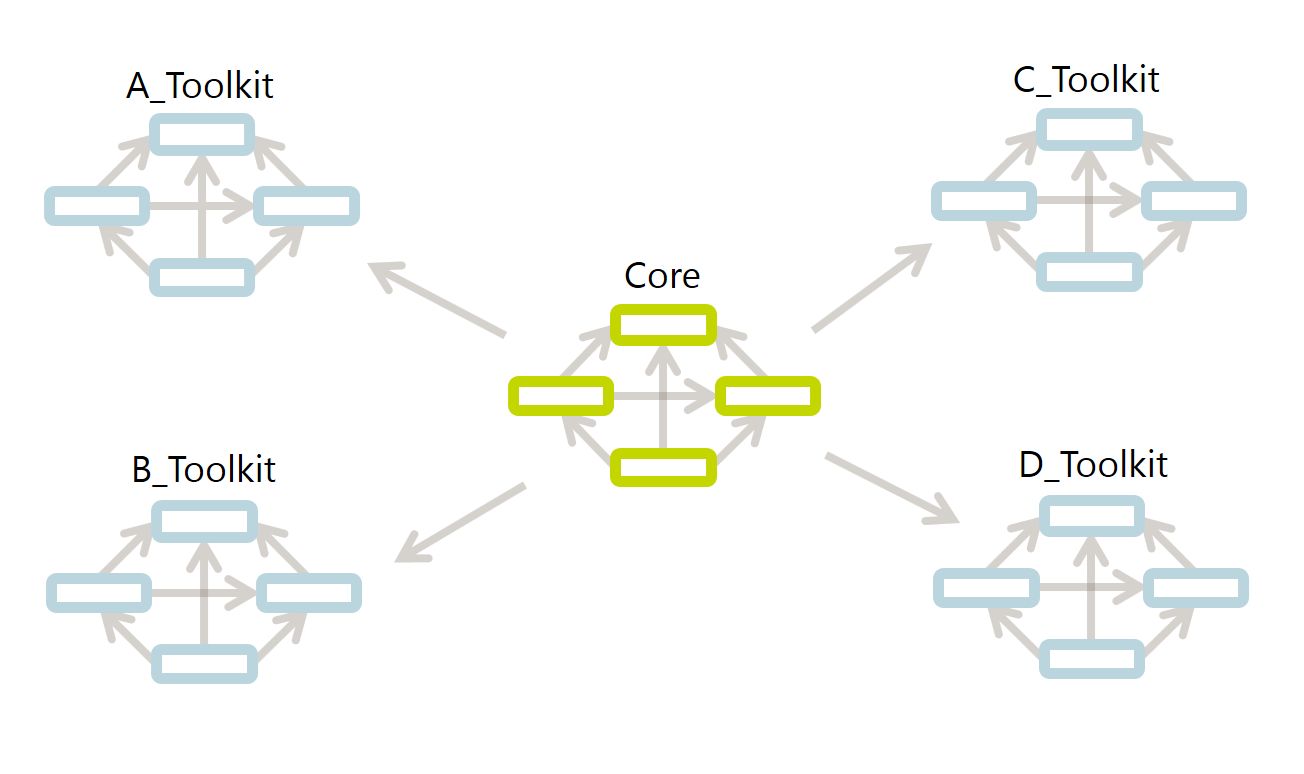
So, what about the few repositories that don't end with _Toolkit then? Understandably, there is also a large collection of code that will be useful in multiple toolkits. All the code that fits that description will be stored in one of the Core repositories. You will find there is one repository for each category of code.
"But, but, why do you have an exploded diamond instead of a single repo for your core?? It would make things more consistent!" That is a valid point but the code in the Core is much larger than any toolkit. Repositories are used to distribute responsibilities between teams of people and to facilitate semi-isolated development. By splitting each category into its own repository, we enable focused sprints with a smaller risk of people stepping on each other's toes.
Note that, while toolkits will always depend on the core, the core should never depend on a toolkit. The toolkits are also fairly independent sets of code so there should be very few dependencies between them.
Further Reading¶
Now that you have a global view of the way the code and the repositories are organised, you might wonder how that translate into you actually writing code either on the core or on a toolkit. Here's where you can find more details on the way each category of code is structured and the conventions you need to follow: