Creation of Datasets¶
Datasets are a way to store and distribute BHoMObjects for use by others. For example, a list of standard structural materials or section properties as well as global warming potential for various materials.
The data should be serialised in a Dataset object, and the relevant .csproj file in the repo, in which the Dataset is stored, should have a post build event implemented that ensures that the Dataset is copied to the C:\ProgramData\BHoM\Datasets folder. This will allow it to be picked up by the Library_Engine.
Generate a new dataset¶
To generate a new dataset to be used with the BHoM the following steps should be taken.
-
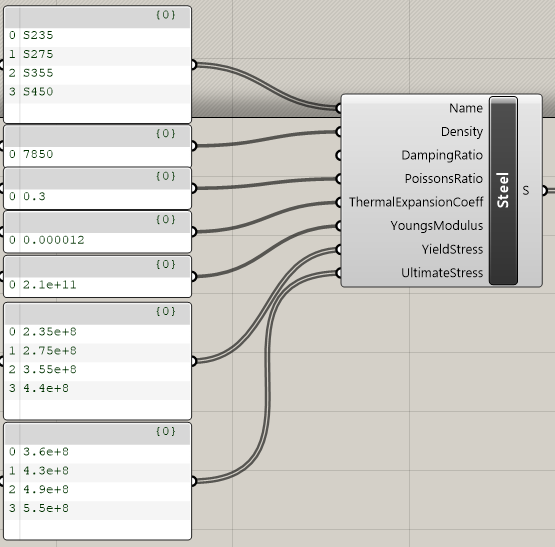
Generate the objects to be stored in the new Dataset. This means creating the BHoMObject of the correct type in any of the supported UIs. See below for an example of how to create a handful of standard European steel materials in Grasshopper. Remember to give the created objects an easily identifiable name as the name is what will show up when using the data in the dropdowns. Remember that all BHoM objects should be defined in SI units.
-
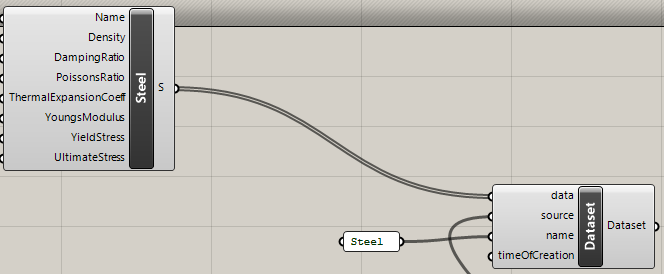
Store the created objects in a Dataset object and give the dataset an appropriate name. This is the name for the dataset - the name that appears in the UI is described the next step.
-
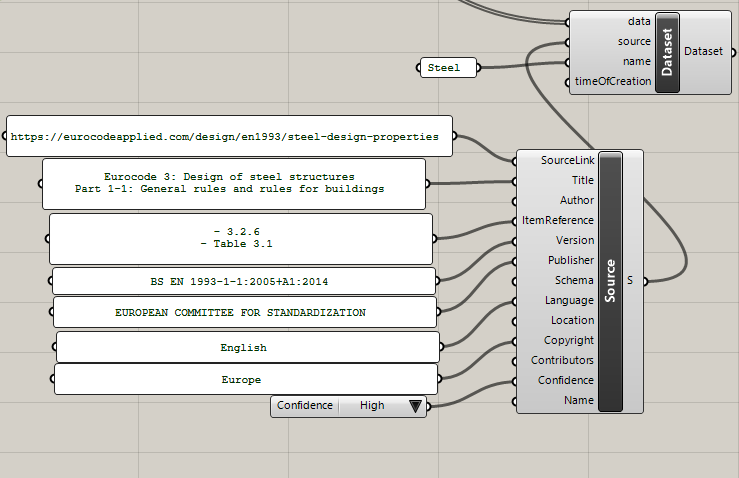
Populate the source object and assign it to the dataset. See guidance below regarding the source.
-
Convert the dataset object and store it to a single line json file. This is easiest done using the FileAdapter. The library engine relies on the json files to be a single line per object, while the default json output from the FileAdapter is putting the json over multiple lines. To make sure the produced json file is in the correct format for the library engine, provide a File.PushConfig with
UseDatasetSerializationset to true andBeautifyJsonset tofalseto the push command. Name the file something clearly identifiable, as the name of the file will be what is used to identify the dataset by the library engine, and will be what it is called in the UI menu.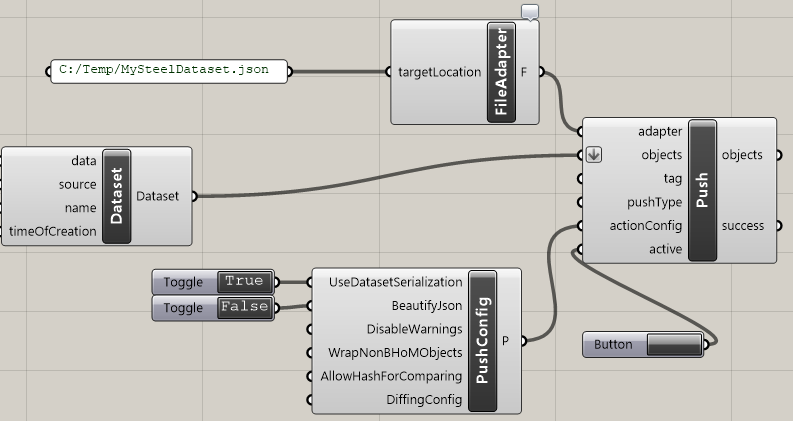
-
For personal use, do one of the following:
- Place the file in the relevant subfolder of the C:\ProgramData\BHoM\Datasets folder. If no relevant subfolder already exists, a new one can be added. The folder will be used to generate the menus used to find the dataset in the menu system, and also makes a whole folder searchable using the Library method. Remember that running an installer will reset the datasets folder so for this option backup the json file, or use option ii.
- Place the json file in a subfolder of a folder of your own choice and use the custom dataset folder outlined below.
- For distribution of the Dataset to the BHoM community do the following:
- Store the dataset in the appropriate repository folder:
- For a general dataset, such as standard materials etc., place the json file in an appropriate subfolder folder in BHoM_Datasets.
- For a toolkit specific dataset put the json file in a Dataset folder in the root folder of the toolkit to host the dataset. If no such folder exist, it should be created. Make sure that the oM project in the toolkit has the following post-build event code:
xcopy "$(SolutionDir)DataSets\*.*" "C:\ProgramData\BHoM\DataSets" /Y /I /Ethat ensures that the dataset is copied over to the C:\ProgramData\BHoM\Datasets folder.
- Raise a Pull request on GitHub and ask for review from relevant parties.
- Store the dataset in the appropriate repository folder:
Custom dataset folder¶
By default, the Library_Engine scans the C:\ProgramData\BHoM\Datasets for all json files and loads them up to be queryable by the UI and the methods in the library engine. This location is reset with each BHoM install to make sure all datasets are up-to-date and that any modifications or fixes correctly are applied to the data. For some cases it can be also useful to have your own datasets stored in your own folder for example on a network drive to share during work on a particular project.
For these reasons it is possible to get the Library_Engine to scan other folders for datasets as well. This can easily be controlled via the AddUserPath and RemoveUserPath commands that can be called from any UI. After the AddUserPath command has been run once for a particular folder, the library engine will store the information about this folder in its settings and will keep on looking in subfolders of that location for any json files to be used as dataset.
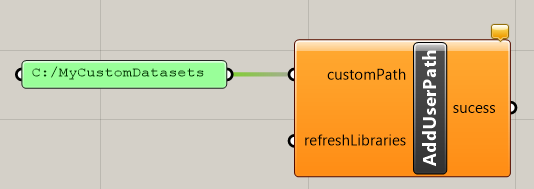
To stop the Library_Engine from looking in this particular folder, use the RemoveUserPath command, providing a link to the folder you no longer want to be scanned by the Library_Engine.
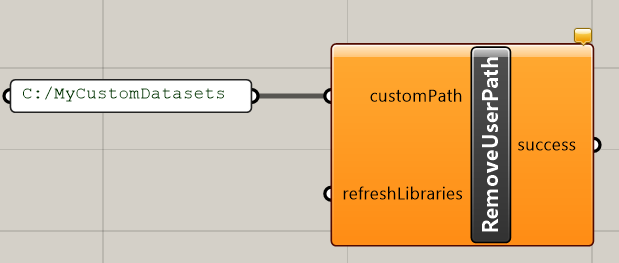
Remember that the menu system of the Dataset dropdown components are built up using the subfolders, so even if only a single dataset is placed in this custom folder it might be a good idea to still put your json file in an appropriate subfolder.